
Connecting
Kubernetes & Docker Part 1 본문
Kubernetes & Docker Part 1
쿠버네티스 기초 다지기 3/e
한정된 자원을 사용하기 위한 노력
1960년대부터 한정된 자원을 효율적으로 사용하고자 하는 시도는 계속되어 왔다. 대표적으로 가상머신이 있는데, Popek와 Goldberg가 "실제 컴퓨터의 효율적이고 고립된 복제물"로 정의되어 현재는 "실제 하드웨어와 직접적인 통신이 없는 가상 컴퓨터"를 가리킨다.
가상머신의 정의
시스템 가상 머신
하드웨어 가상 머신이라고 표현하며, 각 OS를 실행하는 가상 머신 사이의 기초가 되는 물리 PC를 다중화하는 기법을 뜻한다. 가상화를 제공하는 소프트웨어 계층은 가상 머신 모니터 또는 하이퍼 바이저라고 하며, 이를 통해 다음과 같은 이점을 얻을 수 있다.
-
여러 OS를 사용하는 환경은 완벽히 고립된 형태로 같은 PC에 실행할 수 있다.
-
가상 머신은 실제 PC가 제공되는 것과 다른 형대의 명령어 집합 구조(ISA)를 제공한다.
명령어 집합 (Instruct set) 혹은 명령어 집합 구조 (Instruct set architecture, ISA)는 마이크로프로세서가 인식해서 기능을 이해하고 실행할 수 있는 기계어 명령어를 말한다.
명령어 집합 구조를 물리적으로 구현하는 방법을 마이크로아키텍처 혹은 컴퓨터 조직이라고 표현하며, 인텔. AMD는 거의 같은 명령어 집합 구조를 서로 다른 마이크로아키텍처로 구현되어 있다.
- 이렇게 하나의 PC에서 여러개의 가상 머신들을 게스트 OS라고 지칭하게 되며, 장치간 충돌을 방지하기 위해서 가상 머신 소프트웨어는 제품 품질의 고립 (QoS 고립)을 사용한다.
프로세스 가상 머신
VM은 응용 프로그램 가상 머신이라고 부르며, OS 안에서 일반 응용 프로그램을 실행하고 단일 프로세스가 이를 지원하는 형태를 말한다. 어떠한 플랫폼에서도 동일하게 실행하고자 하는 목적으로 개발되었으며, 고급 프로그래밍 언어를 통해 구현되기 때문에 해석기가 필요하다는 특징을 가지고 있다.
이런 종류의 가상 머신은 JVM을 사용하는 JAVA의 인기가 높아지면서 대중화되었으며, 닷넷 프레임워크는 공통 언어 런타임 언어라는 가상 머신을 실행한다.
기술
공통의 실질 적인 하드웨어에서의 네이티브로 실행되는 VM은 전가상화와 반가상화 2가지 분류로 나누어지게 되며, 완전한 가상화 환경을 구축하기 위한 하이퍼바이저가 추가된다. 각 두 가지의 하이퍼바이저의 대한 차이는 본인의 블로그나 다른 블로그에 자세하게 설명되어 있기 때문에 각 내용은 넘어가도록 한다.
네이티브가 아닌 시스템 에뮬레이션의 경우 다른 CPU를 위해 작성된 응용 소프트웨어나 운영 체제가 동작할 수 있도록 하는 형태를 말한다. 예를 들어 ARM 프로세서로 개발된 응용 프로그램을 X86 시스템 에뮬레이터로 실행하거나, DOS 환경에서 만들어진 응용 프로그램을 현대의 PC에서 사용할 수 있도록 하는 방식이 있다.
컨테이너 등장 배경
VM의 한계점
VM의 시장을 주도하고 있는 ESXi, Xen, VirtualBox, KVM은 공통의 물리 PC를 하이퍼바이저를 사용해서 한정된 자원을 공유할 수 있게 가능해지면서 여러 개의 응용 애플리케이션을 운영할 수 있게 되었다. 하지만 단점도 명확하게 존재한다.
첫 번째, VM 위해서 동작하는 호스트 OS는 일반적으로 사용하는 PC환경과 동일한 특성을 가지기 때문에 각 애플리케이션의 사용목적에 따라 설치하는 수동적인 작업이 필수적이며, VM의 개수가 기하급수적으로 증가하게 되면, 이를 수용하기 위한 하드웨어 성능이 높아지게 때문에 비용 증가에 따른 부담이 따르게 된다. 이를 관리하는 관리자 또한 증가하는 VM을 효율적으로 관리할 수 없으므로 업무 효율성을 떨어진다. 관리자의 효율성을 증대하기 위해서 오케스트레이션 기술이 등장하였지만 초장기 오케스트레이션은 복잡성과 낮은 안전성 때문에 득 보다 실이 많은 것이 사실이었다.
두 번째, 동일한 VM 배포의 시간이 오래 걸린다. 서비스를 운영하는 입장에서 안전성을 보장하기 위해서 여러 애플리케이션을 운영하여 하나의 시스템의 동작이 중단되는 사태가 일어나더라도, Fault Tolerant를 보장하기 위해 여러 애플리케이션을 VM환경에서 실행하는 것이 일반적인데, 같은 VM을 복제하고 디플로이 시간이 오래걸린다. 물론, 기존의 VM을 백업받아서 다시 업로드하게 되면 이러한 시간은 많이 단축시킬 수 있겠지만, 동일한 벤더사의 제품을 사용하는 경우가 아닌 다른 벤더사의 제품을 사용하는 환경이라면 백업된 확장자 파일을 지원하지 않을 수 있다. 이러한 경우를 Vendor lock-in이라고 지칭한다. 이와 같이 처음부터 다시 서버를 다시 세팅하는 경우 각 서버의 환경설정이 100% 일치하다고 볼 수 없다.
세 번째, 하나의 애플리케이션 실행을 위해 너무 많은 자원을 사용한다. VM은 호스트 OS 위에서 특정한 애플리케이션을 실행하는 구조를 채택하고 있다. 이런 환경에서 적은 리소스를 사용하는 애플리케이션이라고 가정한다면, 호스트 OS가 사용하는 자원이 더 많을 수 있는 일이 생길 수 있다. 이는 애플리케이션에 특화된 자원 할당을 할 수 없다는 의미가 된다.
컨테이너의 등장
컨테이너를 말하면 처음 드는 생각은 항구에 쌓여있는 철재 박스인 컨테이너가 가장 먼저 생각날 것이다.

육지와 해상 운송 시스템은 전혀 다른 형태로 되어 있기 때문에, 화물을 트럭으로 부두까지 실어오면, 다른 화물들과 함께 부두 노동자가 포장하여 적재하는 방식을 사용하고 있었다. 이는 화물의 손상과 분실, 시간, 비용이 크게 발생하게 되었고, 운송 수단으로는 낮은 신뢰성을 가지게 된 계기가 되었다.
이를 해결하기 위해서 많은 운송업자가 박스 형태로 운송을 시도하였으나 표준이 정해지지 않은 상태에서 서로 독자적인 규격을 사용하면서 결국 대중화에 실패하게 된다.

트럭 운전자였던 말콤 맬린 (Malcolm P. McLean)은 선박에 화물을 적재할 때 걸리는 오랜 대기시간을 해결 학기 위해서 박스만 분리하는 방법을 고안하게 되었고, 선박과 트럭에 공통적으로 사용할 수 있도록 공통 규격의 컨테이너 개발을 시도했다. 결국 1956년 3월 바다와 육지를 포괄한다는 뜻의 Sea-Land 회사를 설립하고 최초로 컨테이너를 활용한 화물운송을 시작하게 되었다. 이는 화물 운송의 혁명을 이끌면서, 2007년 포브스에서 선정한 20세기 후반 세계를 바꾼 인물 15인에 선정되었다.

Docker를 통해 애플리케이션을 구축하는 컨테이너란 용어는 화물 운송 분야에 사용되는 컨테이너에 대한 은유이다. 리눅스나 유닉스, HP, Oracle, IBM에서는 15년 이상 컨테이너와 유사한 기술들을 사용해왔으며, Kubernetis 역시 Google의 Borg 프로젝트에서 유래된 것으로 자신만의 표준 방식으로 사용했으며, 2000년에 들어서서 다양한 컨테이너 기술을 캡슐화하려는 노력이 본격적으로 시작되면서 파편화된 컨테이너 환경을 표준화하려는 시도가 이루어지게 되었다.
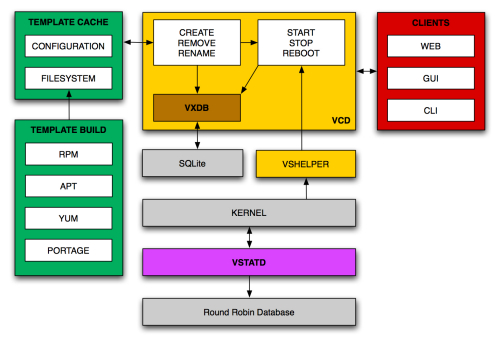
VServer Control Daemon Architecture Overview
2013년 말, dotCloud라는 회사가 컨테이너에 집중하기 위해 Docker로 회사명을 변경하고, 컨테이너 기반의 마케팅을 공격적으로 진행한 결과, 컨테이너 생태계를 부활시켰다. 이를 통해서 VM이 가지고 있었던 대부분의 문제가 해결됨에 따라 이제는 수백, 수천 개로 이루어진 컨테이너를 오케스트레이션과 스케줄링을 할 수 있도록 하는 Docker Swarm, Kubernetes 등 과 같은 플랫폼의 시작이 되었다.
컨테이너란?
컨테이너는 이전의 VM과 비슷한 OS 가상화의 예로 들 수 있다.
- 애플리케이션 가상화
- 네트워크 가상화 (NFV, SDN)
- 데스크톱 가상화 (VDI)
- 스토리지 가상화
또한 위의 4가지 가상화 방식 또한 현재에 인프라 환경에서 가장 많이 사용되는 가상화 분야이기도 하다. 사실 이러한 종류의 기술들은 1960년대부터 시작되었거나 콘셉트가 이미 존재했던 가상화 기술이지만, Docker는 프로세스 수준에서 완벽하게 독립되어 리소스 제어를 위해 chroot, control groups, , Namespace 등 과 같은 리눅스 커널에 내장된 기능을 활용한다는 것이 특징이다.
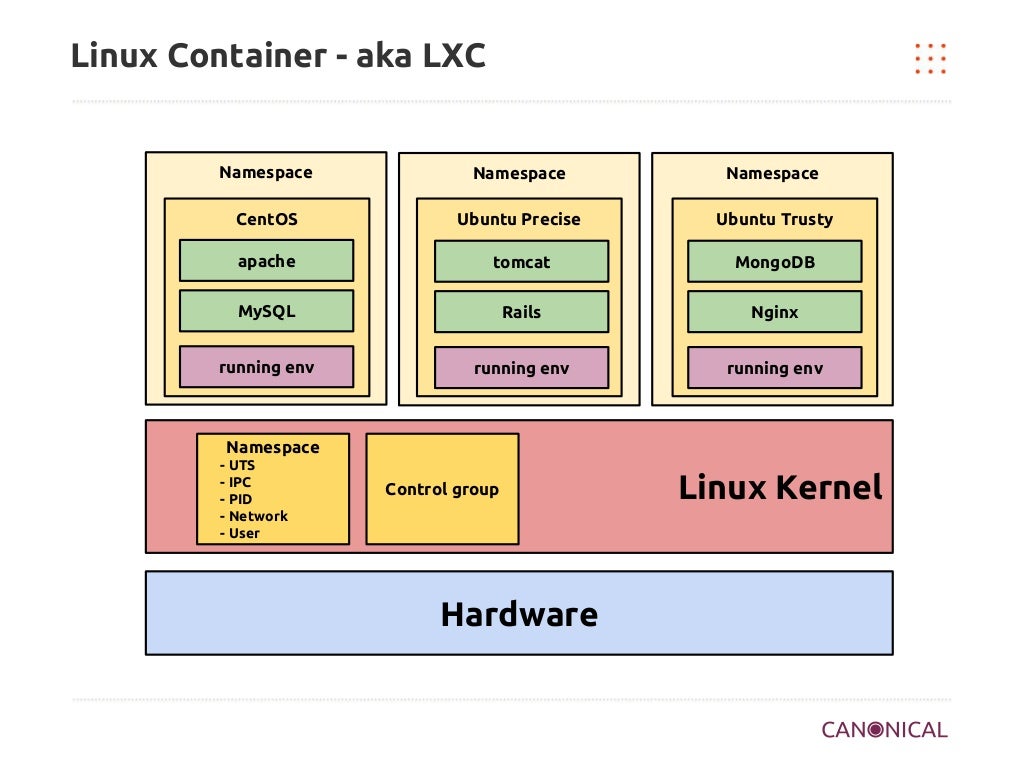

컨테이너는 이러한 기술을 사용해서 필요한 모든 것을 캡슐화시키고, 독립형 프로세스로 동작한다. 해당 이미지 안에는 애플리케이션 바이너리, 시스템 도구, 라이브러리 환경과 기반 구성, 런타임이 포함된다. 이를 통해 개발자나 사용자의 각각 다른 독립적인 플랫폼을 사용 중에 있더라도 동일한 환경에서 독립적으로 실행할 수 있다는 장점이 있다.
또한 독립적인 프로세스로 기존 VM에 비해 상당히 경량화되어 있는 특성 덕분에 신속한 배포와 실행이 가능하다는 장점이 있다.

컨테이너의 핵심 기술
-
컨트롤 그룹 (control groups)
- 각 프로세스 또는 컨테이너가 소비하는 호스트의 리소스를 공유하고 제한한다. 이는 호스트 OS 하드웨어 리소스 서비스 거부 공격을 방지하기 때문에 리소스 활용과 보안에서 가장 중요하다.
- 컨테이너는 사전에 정의한 제약 조건하에 CPU, 메모리 사용량을 공유할 수 있으며, 컨테이너가 I/O 디바이스나, 중요 하드웨어에 대한 접근을 프로비저닝하고 디바이스에 접근한다.
다음은 대표적인 7개의 컨트롤 그룹을 나타낸다.
*Memory 컨트롤 그룹 *
페이지 접근을 그룹별로 추적하며 물리 메모리, 커널 메모리, 전체 메모리에 대한 제한을 정의한다.
Bikio 컨트롤 그룹
블록 디바이스당 read/write 그룹별 I/O사용량을 추적하고 디바이스별 read/write 연산을 바이트 단위로 제한한다.
CPU 컨트롤 그룹
CPU당 사용자 및 시스템 CPU 시간 및 사용량을 추적하며, 가중치는 설정할 수 있지만 한계치는 설정할 수 없다.
Freezer 컨트롤 그룹
자원을 효율적으로 스케줄링하기 위해 작업을 중단하고 시작하는 배치(batch) 관리 시스템에 유용하다.
SIGSTOP 신호는 프로세스를 일시 중단할 때 사용하지만, 프로세스는 일지 중지나 재개 여부는 인식하지 못한다.
CPUset 컨트롤 그룹
멀티 코어 CPU 아키텍처 내의 특정 CPU 그룹을 고정할 수 있다. 이를 통해 애플리케이션별로 CPU를 고정하여 로컬
메모리 접근량을 늘리거나 스레드 전환을 최소화하여 코드의 성능을 향상할 수 있다.
Net_cls/net_prio 컨트롤 그룹
컨트롤 그룹 내의 프로세스에서 생성되는 송신 트래픽 클래스나 우선순위를 지정할 수 있다.
Devices 컨트롤 그룹
장지 노드에 대한 read/write 권한을 제어한다.
-
네임스페이스 (Namespace)
OS 안에 프로세스 상호 작용을 다른 유형으로 격리하기 위해 컨테이너라는 작업 공간을 뜻한다. 리눅스 네임스페이스는 unshare라는 시스템 호출을 통해서 생성하며, clone, setns를 사용하면 unshare와 다른 방법으로 네임스페이스를 조작할 수 있다.
프로세스가 갖는 다른 프로세스와 네트워킹, 파일 시스템 등의 가시성을 제한하며, 컨테이너 프로세스는 동일한 네임스페이스에 있는 것들만 볼 수 있도록 제한되어 있다.

Docker 엔진은 다음과 같은 네임스페이스를 사용한다.
pid
다른 네임스페이스와 독립된 프로세스 ID 집합을 통해 프로세스를 격리한다.
net
loopback 인터페이스를 바탕으로 네트워크 스택을 가상화하여, 네트워크 인터페이스를 관리하며 하나의
네임스페이스에 존재하는 물리 NIC와 가상 NIC를 동시에 만들 수 있다.

ipc
프로세스 사이의 통신에 대한 접근을 관리한다.
mnt
파일 시스템 마운트 지점을 제어하며, 리눅스 커널에 생성된 첫 번째 네임스페이스이며 독점하거나 공유할 수 있다.
uts
유닉스 시간 공유 시스템이라고 부르며, 단일 시스템이 다른 호스트와 도메인 이름 지정 스키마를 다른 프로세스에게
제공할 수 있게 함으로써 버전 ID와 커널을 격리한다.
user
컨테이너의 추가 구성을 하지 않아도 UID/GID를 컨테이너에서 호스트로 맵핑할 수 있다.
-
통합 파일 시스템 (Union FS)
컨테이너의 이미지는 VM과 클라우드와 같이 특정 시점의 상태를 제공하게 되는데 컨테이너의 이미지의 경우 파일 시스템을 스냅샷 형태로 만들기 때문에 VM 이미지의 크기보다 훨씬 작은 크기이다. 컨테이너는 호스트 커널과 공유하며, 일반적으로 매우 적은 프로세스 집합으로 실행되기 때문에 파일 시스템 크기와 부트스트랩 시간이 짧아지게 된다.
통합 파일 시스템은 새로운 파일 시스템을 만들지 않고 새로운 컨테이너를 즉시 생성할 수 있는 copy-on-write 저장소를 사용한다. 이는 시스템에서 필요에 따라 저장소를 할당해서 사용하는 씬(thin) 프로비저닝과 비슷하다고 할 수 있다.

컨테이너를 사용하는 이유
한정된 자원을 효율적으로 사용하기 위한 노력들의 일환으로 Docker 컨테이너가 대세가 되었고, 어떠한 특징과 핵심 기술을 가지고 있는지 살펴보았다. 그럼 우리는 컨테이너를 사용하는 이유는 무엇일까? 사실 컨테이너가 없던 시절 해도 서버는 잘 운영해왔다. 아주 당연한 듯이… 컨테이너를 사용할 수밖에 없는 멋진 이유를 살펴보도록 한다.
인프라 관점
서버를 한 번이라도 운영해본 사람이라면, 혹은 필자와 같이 인프라분야에 대해서 공부하는 학생이라도 서버를 운영함에 있어서 문제가 발생했을 때, 마음대로 해결할 수 없는 경험을 한번쯤 해보았을 것이라 생각한다. 이는 서버를 어떻게 다루는지, 각 서버의 벤더상 스펙, 운영 기록이 다 다르기 때문이다.
따라서 처음에 구축한 서버와 최근에 구입한 서버의 환경이 100% 일치하다고 장담할 수 없다. 이러한 차이점이 결국 장애를 일으키는 원인이 되고, 원인을 찾기 위한 노력이 많이 들어간다. 이렇게 지속적인 패치, 업데이트, 환경 설정 변경이 이루어진 서버를 우리는 Snowflake Servers (눈송이 서버)라고 불린다.

각각의 눈송이 모습이 다 다르고, 한번 설정하고 나면 똑같이 설정하기 어려워 눈송이처럼 녹아버리는 상태를 뜻하는 것이다.
이러한 문제를 해결하기 위해서 사내 내부적으로는 운영 기록을 문서화하여 서버 운용기록을 남기기도 하며, 여러 서버에 동시에 접속하여 한번에 똑같은 명령을 실행하는 tmux-xpanes와 같은 도구를 사용한다.

이러한 작은 차이가 몇 달, 몇 년이 지나게 되면 결국 장애 발생에 심각한 원인이 될 수 있다. 운영자는 오류가 발생했을 때, 해결방법을 찾기 위해서 기존의 작성한 문서를 참고하여 해결하고자 해도, 과거에는 됐으나 현재 시점에서는 안될 수도 있고, 운영 환경의 변경 사항 때문에 정상적으로 실행하지 못할 수도 있다. 따라서 여러 서버의 운영 기록을 코드화 하는 Infrastructure as a code(IaC) 형태의 다양한 시도들이 등장한다.

필자가 현재 인프라 환경에서 사용하는 Ansible부터 다양한 IaC 도구들은 서버의 운영기록을 남기기 위한 의도와 더불어, 다양한 서버의 통합관리 및 동일한 환경을 제공하기 위한 의도가 담겨있다. 이렇게 서버를 코드화해서 운영하게 되면 다음과 같은 장점을 가지게 된다.
1. 서버의 유지보수 및 관리가 용의해진다. - 새로운 서버를 구축시 미리 정의한 코드를 가지고 동일하게 생성하여 확장성이 용의 하다.
- 다른 이가 만든 서버를 소프트웨어를 사용하듯 쉽게 사용할 수 있다.
- 서버 변경이력에 대한 정보를 코드로 쉽게 확인할 수 있다.
CI/CD와 DevOps
빠르게 변화하는 소프트웨어 시장에서 경쟁력을 향상하기 위해서는 고객의 요구조건을 빠르게 수용하기 위해 소프트웨어의 수명주기를 앞당기는 것이 중요하다.

CI/CD에 컨테이너를 함께 사용하게 되면, 개발자 PC에서 만들어진 컨테이너가 사내 테스트 서버에 쉽게 배포할 수 있고 클라우드에 실행되고 있는 상용화 서버에도 쉽게 배포할 수 있는 이점이 생긴다. 이러한 일이 가능한 이유는 앞서 말한 컨테이너의 특성과. 아주 밀접한 연관성을 가지고 있다. 개발 PC, 테스트 서버, 상용 서버에 이르기까지 OS, 패키지, 애플리케이션의 버전의 동일성을. 보장하고, 의존성 충돌이 발생하지 않는다.
이렇게 컨테이너를 사용하면 복잡한 의존성에 대해서 신경 쓰지 않아도 되기 때문에 개발자는 개발에 대해 집중하여 진행할 수 있으며, 이는 업무의 효율성과 안전성 증가에 도움이 된다.
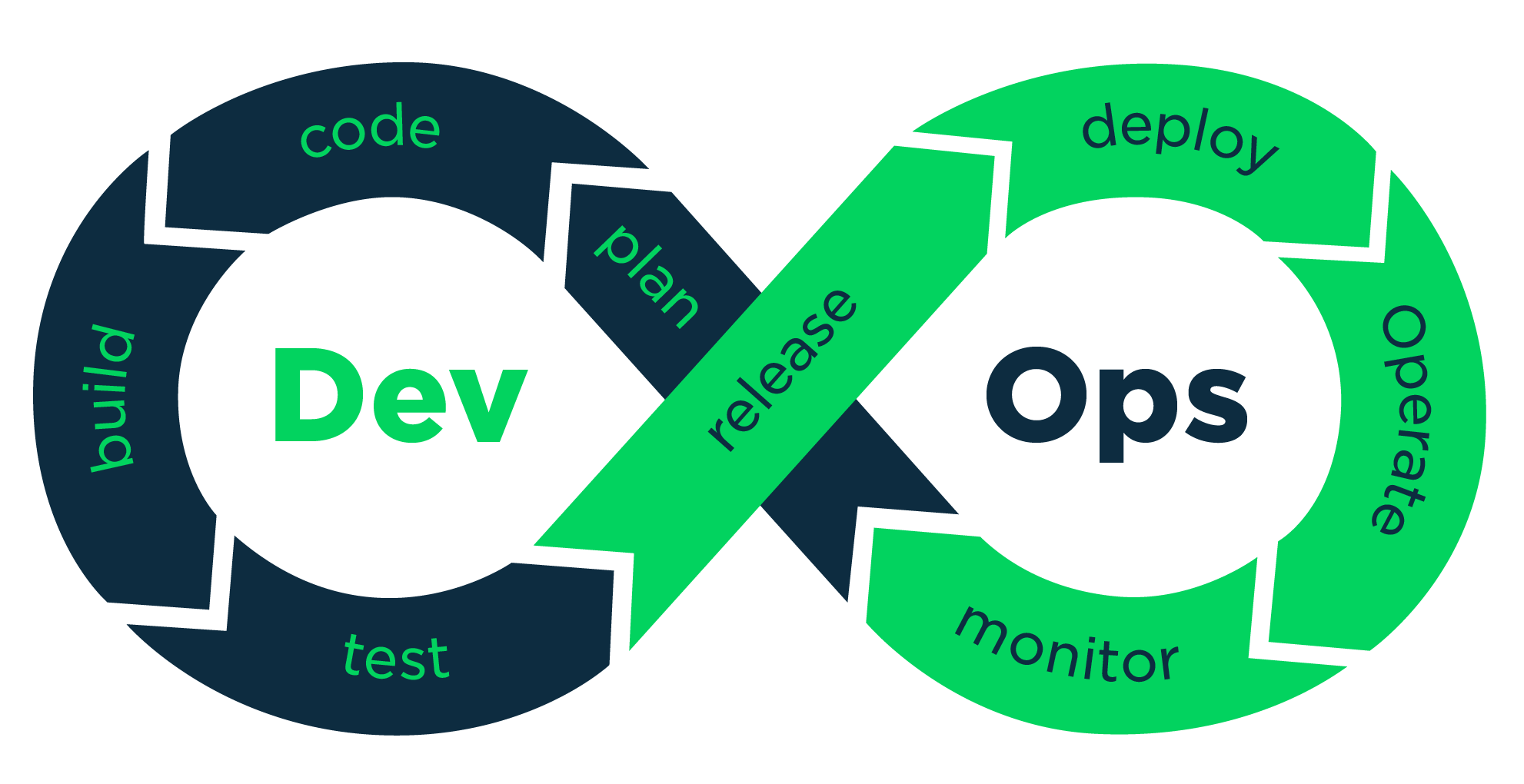
이러한 변화는 DevOps의 성숙에 커다란 기여를 할 수 있다. 과거 DevOps는 정의는 잘되어 있을지라도 실제 운영환경에서 이름만 변경되고 실질적인 변화가 없거나 DevOps라는 이름하에 개발팀에서 운영과 개발을 모두 병행하는 사례도 볼 수 있었다. 하지만 컨테이너가 보편화되면서 개발팀은 CI/CD와 컨테이너를 통해 소프트웨어 품질 향상과 배포 과정을 쉽게 진행할 수 있을 뿐만 아니라 실제 DevOps팀에서는 서버단에서의 플랫폼 자동화와 안정적인 운영에 목적을 두고 운영할 수 있게 되었다.
MSA 발전과 자원할당의 효율성
기존 모놀리식 방식에 비해 현재는 MSA 방식이 점점 성숙해짐에 따라 각 애플리케이션의 한 작업을 담당하는 task의 자원이 작아지면서 기존의 VM보다 적은 자원으로 운영할 수 있게 되었다. 기존 방식을 그대로 사용한다면 1~2 코어 만으로도 충분히 감당할 수 있는 서비스일지라도 게스트 OS의 사양 때문에 필요 이상의 자원을 할당할 수밖에 없고 이는 한정된 자원의 효율성을 떨어뜨리게 된다.
하지만 컨테이너는 서비스별 도메인별 목적에 따라 시스템을 실행할 수 있도록 격리된 구조와 레이어된 파일 시스템을 통해서 해당 서비스의 자원을 효율적으로 사용할 수 있게 되었고, 간소화된 빌드와 배포 과정 덕분에 몇 주에서 며칠이 걸리던 작업을, 단 몇 시간 안으로 단축시킬 수 있게 되었다.
Kubernetes

쿠버네티스는 컨테이너 기반의 오케스트레이션 플랫폼이다. 컨테이너 오케스트레이션 도구는 Docker Swarm, Mesosphere와 같은 다른 기술도 존재하지만 2017년을 기점으로 쿠버네티스는 업계 표준이라고 불릴 만큼 업계 트렌드로 자리 잡았다.

구글은 2014년에 쿠버네티스 프로젝트를 오픈소스로 공개했다. 근데 하나 의문점이 생긴다. Docker 컨테이너가 가장 인기 있으며, 컨테이너를 사용하는 이유를 앞서 계속해서 사용해 왔는데 현재의 트렌드는 Docker에서 공개한 Swarm 대신에 쿠버네티스를 사용하는 것 일까?
쿠버네티스 등장 배경
구글은 과거부터 자신의 서버 자원에 컨테이너 기술을 상용 환경에서 사용하고 있었으며, 이런 컨테이너 환경을 관리하기 위해서 2003년 수만 대의 머신으로 구성된 클러스터를 안정적으로 동작하기 위한 Google Borg 프로젝트를 시작했다. 초창기 Borg는 대규모 클러스터링 환경에서 Borg는 Workload를 관리하는 역할을 담당했다. 이는 OS가 프로세스를 관리하는 것과 유사하게 동작하였는데, OS가 여러 프로세스가 동작하는 과정에서 어떠한 시점에 프로세스를 활성화하고 리소스 부족 현상이 발생할 때 어떠한 프로레스를 멈추거나 죽이는 역할과 비슷하다.
Borg위에 실행되는 애플리케이션이 많아지면서 구글의 직원들은 더 많은 기능을 요구하게 되었고 하나의 생태계를 구성하기까지 이르렀다. 애플리케이션의 자원 요구사항을 추적하고, 환경설정과 업데이트, service discovery, auto-scaliing과 같은 다양한 기능을 추가되었다. 하지만 이러한 다양한 기능이 추가됨에 사용자 입장에서는 몇 가지의 언어와 여러 프로세스 간의 상호작용을 이해하는 과정이 필요했기 때문에 다소 이질적이며, 임시적인 시스템이었다. 하지만 Borg는 규모나 기능이 다양하기 때문에 구글의 기본 컨테이너 관리시스템으로 남아있게 된다.
이후 Omega라는 두 번째 컨테이너 관리 시스템이 만들어지게 되는데 Borg가 다양한 기능과 입증된 패턴들의 집합으로 구성되어 있다면 Omega는 Borg보다 일관되고 원칙적인 아키텍처를 가지기 위해서 탄생되었다. Omega가 하는 대표적인 역할은 낙관적 동시성 제어 (optimistic concurrency control)를 사용하여 스케줄링 시 때때로 발생되는 충돌을 처리하고, 트랜젝션 지향 저장소에 클러스터를 저장하는 구조를 채택하였다. 이는 모놀리식 기반의 중앙 집중식 마스터 방식으로 모든 변경사항을 처리하기보다 각 노드(피어)에게 역할을 분산시킴으로 효율적인 처리가 가능해졌다. 스케줄링 기법에서 많은 변화가 있었던 Omega는 추후 Borg 프로젝트에 흡수되었다.
낙관적 동시성 제어 (optimistic concurrency control)
사용자들이 같은 데이터를 동시에 수정하지 않을 것이라고 가정하고 데이터를 읽을 때 Lock를 설정하지 않는 방식을 말한다.
하지만 사용자가 데이터가 잘못 갱신되도록 신경 쓰지 않는다는 의미는 아니며, 데이터를 수정할 때 앞서 읽은 데이터가 다른 사용자에 의해 변경되었는지를 반드시 검사해야 한다.
이렇게 Borg프로젝트와 Omega프로젝트를 지나 쿠버네티스가 탄생한 계기가 되었다. 쿠버네티스는 키잡이와 파일럿을 뜻하는 그리스어에서 유래되었으며, 이는 governor(통치자)와 cybernetic(인공두뇌학)의 어원이다. 쿠버네티스의 약자로 K8s라고 부르기도 하는데 이는 “ubernete” 8 글자를 “8”로 대체한 것이다.
Kubernetes & Docker Swarm
Docker Swarm은 처음에는 별개의 프로젝트로 진행되었으나 Docker 1.12 버전 이후로 통합되어 간단하게 운영이 가능하도록 변경되었다. Docker에 모든 항목이 통합되어 있기 때문에 설치 및 운영적 측면에서는 Docker Swarm이 Kubernetes보다 우위에 있으며, 간단하게 운영이 가능하다는 장점도 가지고 있다.
이에 반면 Kubernetes의 경우 Docker 환경을 구축하고 Kubernetes까지 추가적으로 환경을 구축해야 한다는 측면에서는 Docker Swarm보다 열위에 있을 수 있으나, 대부분의 퍼블릭 클라우드도 Kubernetes를 본격적으로 정식 지원하기 시작하면서 컨테이너 오케스트레이션 시장에서 절대적 위치에 있다고 표현해도 틀린 말이 아니다.
하지만 일반적으로 간단하게 컨테이너 오케스트레이션 환경을 간단하게 구축하고 싶다면 Docker Swarm으로도 아주 빠르고 간단하게 구축할 수 있으며, Portainer와 함께 사용한다면 Kubernetes와 거의 유사한 환경으로 구축이 가능하다. 물론 컨테이너 클러스터링에 미세한 성능 조정과 앞으로 학습할 Kubernetes의 여러 이점을 살펴보면 왜 Kubernetes가 업계 표준으로 자리 잡았는지 알 수 있겠지만 그렇다고 해서 무조건 본인의 환경을 Kubernetes로 변경하는 것은 조금 생각할 필요가 있다는 것을 알아 둘 필요가 있다.
Docker Swarm도 충분히 성능과 안전성 측면에서 인정받은 오케스트레이션 도구이다. 자신의 환경과 구성 설계 방식에 따라 언제든지 구성 방식은 변경될 수 있다는 점은 반드시 참고 바라며, 어느 특정 기술에만 종속적인 것이 반드시 좋은 것만이 아니라는 사실을 꼭 기억해 주었으면 좋겠다.
'kubernetes' 카테고리의 다른 글
| Mac OS에서 minikube 사용하기 Part 1 (0) | 2020.01.20 |
|---|---|
| Kubernetes 기본 명령어 사용하기 (0) | 2019.09.10 |
| Kubernetes Installation & Setting (0) | 2019.08.28 |
| GCP를 활용한 K8s Application (0) | 2019.08.16 |
| Kubernetes & Docker Part 2 (0) | 2019.08.06 |
